Go进阶47:从零开始构建全文搜索引擎(译)
原文:Let’s build a Full-Text Search engine
全文搜索是人们每天都在不知不觉中使用的工具之一. 如果您曾经用Google搜索’golang cover report’或试图在电商网站上找到’indoor wireless camera’,则使用了某种全文本搜索. 全文搜索(FTS)是一种用于搜索文档集合中的文本的技术.文档可以指网页,报纸文章,电子邮件或任何结构化文本.
今天,我们将构建自己的FTS引擎.阅读全文之后,我们将能够在1ms内在百万级别的文档中搜索到我们要的结果. 我们将从简单的搜索查询开始,例如:给我所有包含’cat’这个单词的文档,并且我们将扩展engine以支持更复杂的bool查询. 值得注意的是,比较著名的全文搜索引擎(FTS)有Lucene/ElasticSearch/Solr.
看完这篇文章之后,您将学会怎么实现全文搜索和Invert Index 倒序索引. 倒序索引:简单的说,倒序索引的倒序,指的是这个索引是从关键词中查找对应的源的,而不是从源中检索对应的关键词.
1. 什么是FTS(Full Text Search)?
全文检索是一种将文件中所有文本与检索项匹配的文字资料检索方法.全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的. 这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search).
在我们开始编写代码之前,您可能会问:我们不能只使用grep 或者 for-loop来检测文档中是否包含某个单词吗?
我们缺失可以这样来搜索某个单词,但是上面的方法在某些场景下不是最优的方案.
2. 开发的语料库
我们将搜索英语维基百科摘要的一部分.最新dump文件保存在dumps.wikimedia.org. 截至今天,解压缩后的文件大小为913 MB. XML文件包含60万多个文档.
2.1 语料库文件内容样本:
<title>Wikipedia: Kit-Cat Klock</title>
<url>https://en.wikipedia.org/wiki/Kit-Cat_Klock</url>
<abstract>The Kit-Cat Klock is an art deco novelty wall clock shaped like a grinning cat with cartoon eyes that swivel in time with its pendulum tail.</abstract>
2.2. 加载语料库文件
首先我们需要把语料库文件加载到程序中,使用golang标准库encoding/xml package是非常方便的.代码如下
import (
"encoding/xml"
"os"
)
type document struct {
Title string `xml:"title"`
URL string `xml:"url"`
Text string `xml:"abstract"`
ID int
}
func loadDocuments(path string) ([]document, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
defer f.Close()
dec := xml.NewDecoder(f)
dump := struct {
Documents []document `xml:"doc"`
}{}
if err := dec.Decode(&dump); err != nil {
return nil, err
}
docs := dump.Documents
//为了简单起见我们使用文档的index作为ID.
for i := range docs {
docs[i].ID = i
}
return docs, nil
}
每个加载的文档都会分配一个唯一的标识符(UUID).为简单起见,第一个加载的文档被分配了ID = 0,第二个ID = 1,依此类推.
3. 第一版搜索引擎
3.1 搜索内容
现在我们已将所有文档加载到内存中,我们可以尝试查找有cat 的文档.首先,让我们遍历所有文档并检查它们是否包含子字符串 cat:
func search(docs []document, term string) []document {
var r []document
for _, doc := range docs {
if strings.Contains(doc.Text, term) {
r = append(r, doc)
}
}
return r
}
在我的笔记本电脑上,搜索需要103ms(耗时还可以).如果从console output中检查这些文档, 您可能会注意到search函数匹配的结果中包含 caterpillar和category, 但与Cat的大写字母C不匹配.那这些结果不是我想要的.
我们需要先解决两个问题:
- 使搜索不区分大小写(因此Cat也匹配).
- 在单词边界而不是在子字符串上匹配(因此,caterpillar和category不应该被匹配到).
3.2 使用正则表达式进行搜索
来解决上面的连个问题,正则表达式是一种很快被想到和可以快捷实现的方案.
正则表达式是这样的:(?i)\bcat\b
(?i)使正则表达式不区分大小写\b匹配单词边界(一侧是单词字符而另一侧不是单词字符的位置)
实现代码如下:
func search(docs []document, term string) []document {
re := regexp.MustCompile(`(?i)\b` + term + `\b`) // Don't do this in production, it's a security risk. term needs to be sanitized.
var r []document
for _, doc := range docs {
if re.MatchString(doc.Text) {
r = append(r, doc)
}
}
return r
}
😂,搜寻过程耗时超过2s.如您所见,即使有60万个文档,情况也开始变慢.尽管该方案易于实施,但伸缩性不佳(性能不佳). 随着数据集变得越来越大,我们需要扫描越来越多的文档.该算法的时间复杂度是线性的-扫描所需的文档数等于文档总数. 如果我们有600万个文档而不是600万个文档,则搜索将花费20秒.我们需更一步优化.
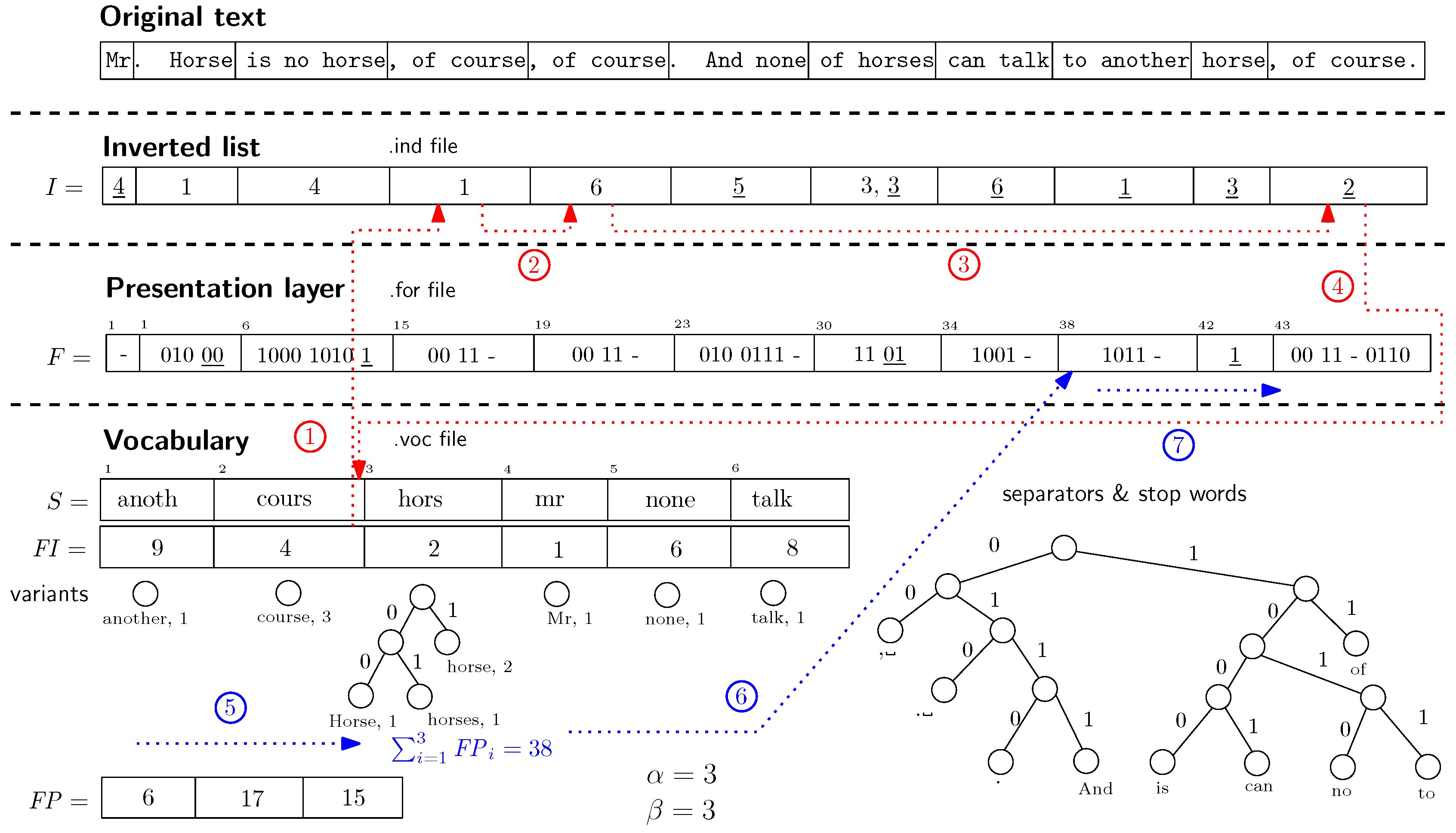
4.倒序索引(Inverted Index)
倒排索引(Inverted index),也常被称为反向索引,置入档案或反向档案,是一种索引方法, 被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射.它是文档检索系统中最常用的数据结构. 有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表.
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置. 后者的形式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建.
为了使搜索查询更快,我们将对文本进行预处理并预先建立索引.
FTS的核心是倒排索引的数据结构.倒排索引将文档中的每个单词与包含该单词的文档相关联.
Example:
documents = {
1: "a donut on a glass plate",
2: "only the donut",
3: "listen to the drum machine",
}
index = {
"a": [1],
"donut": [1, 2],
"on": [1],
"glass": [1],
"plate": [1],
"only": [2],
"the": [2, 3],
"listen": [3],
"to": [3],
"drum": [3],
"machine": [3],
}
下面图是一个倒序索引的示例,书的索引表示单词所在的页码.

5. 文本分析
在开始建立索引之前,我们需要将原始文本分解成适合于索引和搜索的单词(token)列表.
文本分析器由一个Tokenizer和多个Filter组成.
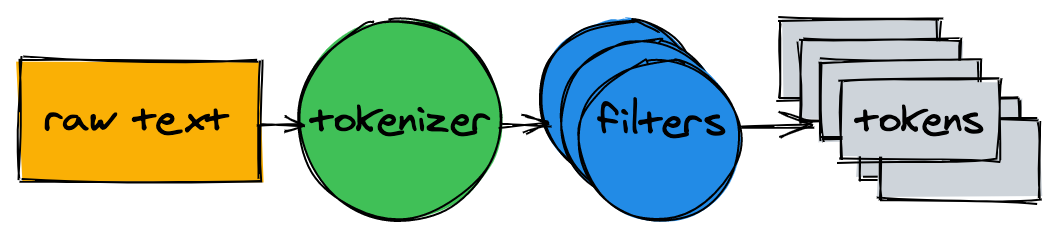
5.1 标记生成器Tokenizer
Tokenizer是文本分析的第一步.它的工作是将文本转换为Token列表.我们的实现在单词边界上分割文本并删除标点符号:
func tokenize(text string) []string {
return strings.FieldsFunc(text, func(r rune) bool {
// Split on any character that is not a letter or a number.
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
})
}
> tokenize("A donut on a glass plate. Only the donuts.")
["A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"]
5.2 构建筛选器Filter
在大多数情况下,仅将文本转换为Token列表是不够的.为了使文本更易于索引和搜索,我们需要进行其他标准化.
5.3 Filter-Lower-Case
为了使搜索不区分大小写,小写过滤器将标记转换为小写.将cat,cat和caT标准化为cat.稍后,当我们查询索引时,我们也将小写搜索词.这将使搜索词cAt与文本Cat匹配.
func lowercaseFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = strings.ToLower(token)
}
return r
}
> lowercaseFilter([]string{"A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"})
["a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"]
5.4 Filter-Common-Word
几乎所有英文文本都包含常用的单词,例如a,I,the或be.这样的词称为stop word. 我们将删除它们,因为几乎所有文档都将匹配stop word. 世上没有stop word的“官方”列表.让我们排除最常用单词排名中的前10名. 我们也可可以随时添加更多:
var stopwords = map[string]struct{}{ // I wish Go had built-in sets.
"a": {}, "and": {}, "be": {}, "have": {}, "i": {},
"in": {}, "of": {}, "that": {}, "the": {}, "to": {},
}
func stopwordFilter(tokens []string) []string {
r := make([]string, 0, len(tokens))
for _, token := range tokens {
if _, ok := stopwords[token]; !ok {
r = append(r, token)
}
}
return r
}
> stopwordFilter([]string{"a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"})
["donut", "on", "glass", "plate", "only", "donuts"]
5.5 Filter-Stemmer
由于语法规则,文档可能包含同一单词的不同形式.stemmer将单词还原为基本形式.例如,fishing,fished和fisher可能被简化为基本形式(stem)fish.
编写Filter-Stemmer是一项艰巨的任务,本文不做介绍.我们将采用现有一个现有的package:
import snowballeng "github.com/kljensen/snowball/english"
func stemmerFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = snowballeng.Stem(token, false)
}
return r
}
> stemmerFilter([]string{"donut", "on", "glass", "plate", "only", "donuts"})
["donut", "on", "glass", "plate", "only", "donut"]
注意:词根化(stemmer)并不总是有效的.例如,有些stemmer肯会把airliner转化为 airlin.
5.6 组装全部Filter
func analyze(text string) []string {
tokens := tokenize(text)
tokens = lowercaseFilter(tokens)
tokens = stopwordFilter(tokens)
tokens = stemmerFilter(tokens)
return tokens
}
Tokenizer和Filter将句子转换为标 token list:
> analyze("A donut on a glass plate. Only the donuts.")
["donut", "on", "glass", "plate", "only", "donut"]
6. 构建索引Invert Index
返回倒排索引.它将文档中的每个单词映射到文档ID.golang 标准库内置map是存储映射的不错选择.映射中的键是令牌(字符串),值是文档ID的列表:type index map[string][]int
构建索引包括分析文档并将其ID添加到map:
func (idx index) add(docs []document) {
for _, doc := range docs {
for _, token := range analyze(doc.Text) {
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(idx[token], doc.ID)
}
}
}
func main() {
idx := make(index)
idx.add([]document\{\{ID: 1, Text: "A donut on a glass plate. Only the donuts."\}\})
idx.add([]document\{\{ID: 2, Text: "donut is a donut"\}\})
fmt.Println(idx)
}
生效了!映射中的每个token都引用包含token的文档的ID:
map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]]
7. 查询Query
要查询索引,我们将应用与索引相同的tokenizer和filter:
func (idx index) search(text string) [][]int {
var r [][]int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
r = append(r, ids)
}
}
return r
}
> idx.search("Small wild cat")
[[24, 173, 303, ...], [98, 173, 765, ...], [[24, 51, 173, ...]]
最后,我们可以找到所有包含cat的文档.搜索600K文档不到一毫秒(18µs)!
使用倒排索引,搜索查询的时间复杂度与搜索token的数量呈线性关系.在上面的示例查询中,除了分析输入文本外,搜索仅需要执行三个map查找.
8. Boolean Query 布尔查询
上一节中的查询为每个token返回了一份脱节的文档列表.
我们通常希望在搜索框中键入small wild cat时找到的结果是同时包含small,wild和cat的结果列表.
下一步是计算列表之间的交集.这样,我们将获得与所有token匹配的文档列表.
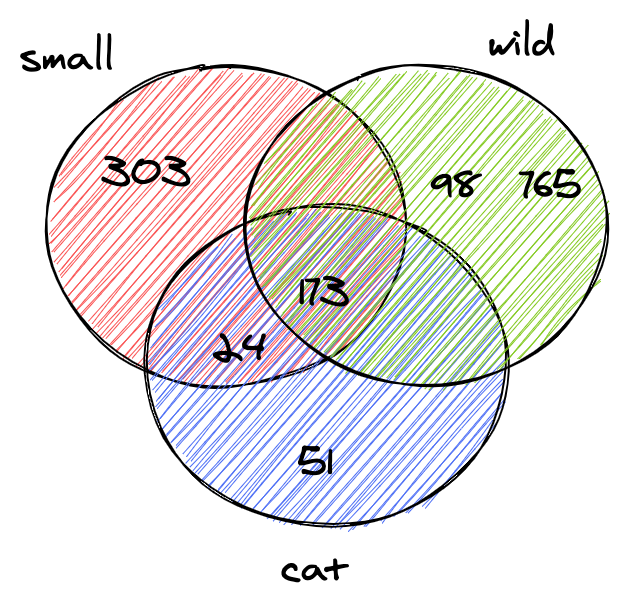
幸运的是,倒排索引中的ID按升序插入.由于ID已排序,因此可以在线性时间内计算两个列表之间的交集.
intersection方法同时迭代两个列表和收集的ID同时存在于两个:
func intersection(a []int, b []int) []int {
maxLen := len(a)
if len(b) > maxLen {
maxLen = len(b)
}
r := make([]int, 0, maxLen)
var i, j int
for i < len(a) && j < len(b) {
if a[i] < b[j] {
i++
} else if a[i] > b[j] {
j++
} else {
r = append(r, a[i])
i++
j++
}
}
return r
}
更新后的search将分析给定的查询文本,查找token并计算ID列表之间的交集:
func (idx index) search(text string) []int {
var r []int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
if r == nil {
r = ids
} else {
r = intersection(r, ids)
}
} else {
// Token doesn't exist.
return nil
}
}
return r
}
Wikipedia转储仅包含两个同时匹配small,wild和cat的文档:
> idx.search("Small wild cat")
130764 The wildcat is a species complex comprising two small wild cat species, the European wildcat (Felis silvestris) and the African wildcat (F. lybica).
131692 Catopuma is a genus containing two Asian small wild cat species, the Asian golden cat (C. temminckii) and the bay cat.
搜索的结果正是我们预期的!
9. 结论
我们刚刚构建了全文搜索引擎.尽管它很简单,但它可以为更高级的项目打下坚实的基础. 我没有涉及很多可以显着提高性能并使引擎更友好的东西.这里有一些进一步改进的想法:
- 将索引保留到磁盘.在每次重新启动应用程序时重建它可能需要一段时间.
- 扩展布尔查询以支持
OR和NOT. - 试用内存和CPU效率高的数据格式来存储文档ID集,A better compressed bitset: Roaring Bitmaps.
- 支持索引多个文档字段.
- 按相关性对结果进行排序.
完整的源代码可在GitHub上找到 akrylysov/simplefts. 原文地址:https://artem.krylysov.com/